
2022년 09월 13일부터 18일까지 서울특별시교육청 교류협력국 교육정보화 지원사업(KLIC)의 일환으로 몽골에 국외 출장을 다녀왔다.
몽골에 가기 전 기대했던 바는 광활한 초원과 함께하는 시원시원한 도로였다. 칭기즈 칸 국제공항에 내렸을 때 기대했던 그대로의 풍경을 보고 큰 감동을 받았다.

하지만 몽골의 수도, 울란바토르에 도착하니... 서울보다 훨씬 더 극심한 교통체증을 가지고 있었다. 20km 이동하는데 2시간... 말이 되냐고요
(울란바토르는 본래 수용인원을 50만명으로 계획했으나, 현재는 150만명이 넘게 살고 있어서 그렇다고 함)

그래서 몽골에 있을 때부터 계속 궁금했던 서울과 울란바토르의 교통사고 사망자, 부상자를 비교해보고 싶었고 이제야 데이터를 수집하고 분석하여 그래프를 그려보았다.
몽골 데이터
우선, 몽골에서 아래의 사이트를 통해 다양한 데이터를 제공하고 있었으며, 이번에 활용한 데이터, 도로교통사고로 인한 사망 및 부상자 수(울란바토르)도 해당 사이트에서 가져왔다.
Статистикийн мэдээллийн нэгдсэн сан
Статистикийн мэдээллийн нэгдсэн сан
1212.mn
서울 데이터
서울 데이터도 아래의 두 사이트에서 가져왔다.
[TAAS 교통사고분석시스템_OECD국가교통사고 발생현황]
http://taas.koroad.or.kr/sta/acs/gus/selectOecdTfcacd.do?menuId=WEB_KMP_OVT_MVT_TAC_OAO
TAAS 교통사고분석시스템
교통사고비교 교통사고 통계를 한눈에 볼수 있습니다.
taas.koroad.or.kr
[서울 열린데이터 광장_서울시 주민등록인구 (구별) 통계]
https://data.seoul.go.kr/dataList/419/S/2/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
참고가 되었던 데이터
데이터를 수집하며 OECD 가입국의 교통사고와 관련된 데이터를 볼 수 있는 곳이 있었다.
http://taas.koroad.or.kr/sta/acs/gus/selectOecdTfcacd.do?menuId=WEB_KMP_OVT_MVT_TAC_OAO
TAAS 교통사고분석시스템
교통사고비교 교통사고 통계를 한눈에 볼수 있습니다.
taas.koroad.or.kr
하지만 몽골은 OECD 가입국에 해당하지 않아 이를 활용할 수 없었다.
대신 위 자료에서 얻은 아이디어는 교통사고 사망자, 부상자를 인구 10만명 당으로 표현하는 것이었다.
각 도시의 인구 10만명 당 교통사고 사망자와 부상자를 표로 나타내보았다.


본격적인 분석 전 데이터 분석에 방해를 주는 이상치를 찾고자 했고, 박스플롯으로 그려보았다.
(박스플롯 위 아래에 수염 같은 선이 있는데, 이 선 밖에 있으면 이상치)

울란바토르 부상자에 이상치가 있었고, 확인해보니 2021년도에 부상자가 월등히 많아 이상치에 해당했다. 그래서 데이터 분석을 할 때는 2021년 데이터는 제외하고 2010~2020년까지의 데이터를 바탕으로 분석했다.
(2021년에는 무슨 일이 있었던거지?!)
분석 전 예상했던 바는 울란바토르의 교통사고 사망자와 부상자 수가 월등히 많을 것이다 였다.
하지만 표로 살펴본 결과
교통 사고 사망자 수 : 서울 > 울란바토르
교통 사고 부상자 수 : 서울 >>> 울란바토르
믿을 수 없는 결과에 몽골 데이터에 있는 사망자와 부상자 수의 단위가 명이 아닌 100명일 것이라 생각했다. 하지만 몽골 사이트에 들어가 메타 데이터를 확인한 결과 명이 맞다...
그래프로도 나타내보니


허허허허....
그.러.면!
교통사고가 났을 때 사망자와 부상자의 비율은 어떠할까?!
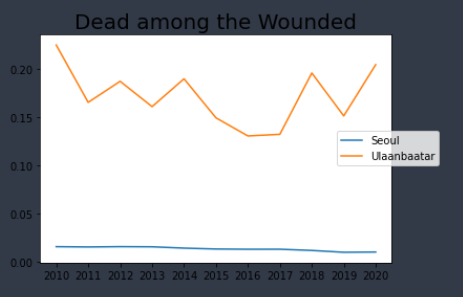
교통사고가 나면 울란바토르에서 더 크게 사고가 난다는 것을 알 수 있었다.
이번 데이터 분석을 하면서 진짜 ???가 수백개가 더 붙었다.
왜 서울이 더 사고가 많이 나지?
서울이 울란바토르보다 운전 속도가 상대적으로 빠른 것 같은데... 왜 사망자는 울란바토르가 더 많지?
몽골 자체에서 수집한 데이터가 정확한 것이 맞나?
부상자와 사망자 데이터는 병원에 가서 치료 받은 사람인가?
몽골에서는 교통사고가 났을 때 병원에 잘 안가나?
데이터 분석을 하고 난 후에도 이러한 물음들이 가시질 않는다... 혼란혼란...
아래는 소스 코드
#디렉토리 파일 확인
import os
path_dir = os.getcwd()
file_list = os.listdir(path_dir)
#데이터 불러오기
import pandas as pd
df_kr_accident = pd.read_excel(file_list[1])
df_mn_accident = pd.read_excel(file_list[-3])
df_kr_census = pd.read_excel(file_list[-1])
df_mn_census = pd.read_excel(file_list[-2])
#서울 인구수 데이터 정제
df_kr_census_trans = df_kr_census.transpose() #행과 열 바꾸기
df_kr_census_trans = df_kr_census_trans.iloc[2:,1] #필요한 행, 열 추출
df_kr_census_trans = pd.DataFrame(df_kr_census_trans) #DataFrame 형태로 다시 바꾸기(하나의 열만 추출하니 형태가 바뀜)
df_kr_census_trans.columns = ["서울_인구수"] #열 이름 변경
#울란바토르 인구수 데이터 정제
df_mn_census_trans = df_mn_census.transpose() #행과 열 바꾸기
df_mn_census_trans.columns = ["울란바토르_인구수"] #열 이름 설정하기
df_mn_census_trans = df_mn_census_trans.iloc[1:, :] #필요한 행만 필터링
#한국 교통사고 데이터 정제(사망, 부상)
df_kr_accident_trans = df_kr_accident.transpose() #행과 열 바꾸기
df_kr_accident_trans.index = df_kr_accident_trans.iloc[:, 1] #행 이름 설정(연도로)
df_kr_accident_trans.columns = df_kr_accident_trans.iloc[0, :] #열 이름 설정
df_kr_accident_trans.columns.name = "year"
df_kr_accident_trans = df_kr_accident_trans.iloc[1:, 3:5] #사망자, 부상자 데이터만 추출
#울란바토르 교통사고 데이터 정제(사망, 부상)
df_mn_accident_trans = df_mn_accident.transpose() #행과 열 바꾸기
df_mn_accident_trans.columns = ["사망", "부상"]
df_mn_accident_trans = df_mn_accident_trans.iloc[2:,:]
#울란바토르_사망, 부상, 인구수 합치기
df_mn_all = pd.concat([df_mn_accident_trans, df_mn_census_trans], axis=1)
#서울_사망, 부상, 인구수 합치기
df_kr_all = pd.concat([df_kr_accident_trans, df_kr_census_trans], axis=1)
#서울 데이터 숫자 데이터로 변환
import re
for i in range(df_kr_all.shape[1]-1):
for j in range(len(df_kr_all.iloc[:, i])):
df_kr_all.iloc[:, i][j] = float(df_kr_all.iloc[:, i][j].replace(",", ""))
#몽골_사망, 부상, 인구수 합치기
df_mn_all = pd.concat([df_mn_accident_trans, df_mn_census_trans], axis=1)
#인덱스 숫자로만
list_index_ts = []
for i in range(len(df_mn_all.index)):
list_index_ts.append("".join(re.findall("\d+", df_mn_all.index[i])))
df_mn_all.index = list_index_ts
#파생변수 생성
df_kr_all["10만명 당 사망자"] = df_kr_all["사망"]/df_kr_all["서울_인구수"] * 100000
df_kr_all["10만명 당 부상자"] = df_kr_all["부상"]/df_kr_all["서울_인구수"] * 100000
df_kr_all["부상자 중 사망자"] = df_kr_all["사망"]/df_kr_all["부상"]
df_mn_all["10만명 당 사망자"] = df_mn_all["사망"]/df_mn_all["울란바토르_인구수"] * 100000
df_mn_all["10만명 당 부상자"] = df_mn_all["부상"]/df_mn_all["울란바토르_인구수"] * 100000
df_mn_all["부상자 중 사망자"] = df_mn_all["사망"]/df_mn_all["부상"]
#그래프 그리기
import matplotlib.pyplot as plt
#박스플롯으로 이상치 확인하기
f, axes = plt.subplots(2,2)
axes[0,0].boxplot(df_kr_all["10만명 당 사망자"])
axes[0,0].set_title("Seoul Dead")
axes[0,1].boxplot(df_kr_all["10만명 당 부상자"])
axes[0,1].set_title("Seoul Wounded")
axes[1,0].boxplot(df_mn_all["10만명 당 사망자"])
axes[1,0].set_title("Ulaanbaatar Dead")
axes[1,1].boxplot(df_mn_all["10만명 당 부상자"])
axes[1,1].set_title("Ulaanbaatar Wounded")
#이상치 확인 결과 2021년이 이상치
df_mn_all
#10만명 당 사망자 그래프
plt.plot(df_kr_all["10만명 당 사망자"][:-1], label = "Seoul")
plt.plot(df_mn_all["10만명 당 사망자"][:-1], label = "Ulaanbaatar")
plt.title("Dead per 100,000", size=20)
plt.legend(bbox_to_anchor=(1.15, 0.85))
#10만명 당 부상자 그래프
plt.plot(df_kr_all["10만명 당 부상자"][:-1], label = "Seoul")
plt.plot(df_mn_all["10만명 당 부상자"][:-1], label = "Ulaanbaatar")
plt.title("Wonded per 100,000", size=20)
plt.legend(bbox_to_anchor=(1.15, 0.85))
#사망자 : 부상자 그래프
plt.plot(df_kr_all["부상자 중 사망자"][:-1], label = "Seoul")
plt.plot(df_mn_all["부상자 중 사망자"][:-1], label = "Ulaanbaatar")
plt.title("Dead among the Wounded", size=20)
plt.legend(bbox_to_anchor=(1.15, 0.6))'데이터 분석' 카테고리의 다른 글
| [데이터분석]"월별" 환율과 코스피, 코스닥은 관계가 있을까? (0) | 2022.11.01 |
|---|---|
| [데이터분석]엔화, 달러, 위안화는 함께 오를까? (0) | 2022.10.26 |
| [데이터분석]진짜 요즘 초, 중, 고등학생들은 키가 더 클까? (0) | 2022.09.21 |
| [데이터분석]KTX, SRT 예매 경쟁률은 어느 정도일까? (2) | 2022.09.12 |
| [데이터분석]연도와 태풍 발생량은 상관이 있을까?(feat. 힌남노) (1) | 2022.09.06 |




댓글