
요즘 길거리를 다니다보면 초, 중, 고등학생들의 키가 굉장히 커서 깜짝깜짝 놀라곤 한다.
라떼는 안그랬던 것 같은데...
급궁금해져서 아래의 사이트에 있는 데이터를 활용해서 키를 분석했다.
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
위 데이터는 2001년부터 2019년까지 있으며 역시나 공적 기관에서 다루는 데이터라 그런지 데이터에 오류가 없었다.
바로 분석 시작!
#참고
-그래프에 보이는 점 : 통계사이트에서 가져온 데이터 값
-꺾은선 : 위 데이터 값을 연결한 것
-직선 : 위 데이터 값을 회귀분석하여 년도와 키의 상관관계를 살펴본 것
*초, 중, 고등학교 남학생 키(Height)

초, 중학교 남학생 키는 지속적으로 증가했다.
고등학교 남학생 키는 변화가 없었다.
*초, 중, 고등학교 여학생 키(Height)

초, 중학교 여학생 키는 지속적으로 증가했다.
고등학교 여학생 키는 변화가 없었다.
여기에 추가적으로 요즘 학생들의 비만율도 문제가 된다는 이야기를 들어 BMI를 살펴보기로 했다.
*BMI(Body Mass Index, 체질량지수) : 몸무게를 키 제곱으로 나눈 값으로 국내에서 사용되는 비만 측정 지표
대한비만학회에 따르면 BMI 기준은
-과체중 : BMI >= 23
-1단계 비만 : 29.9 > BMI >= 25
-2단계 비만 : 34.9 > BMI >= 30
-3단계 비만 : BMI >= 35
이다.
*초, 중, 고등학교 남학생 BMI

초, 중, 고등학교 남학생 모두 BMI 수치가 증가하고 있다.
특히 고등학교 남학생의 경우 평균적으로 과체중에 해당한다.
*초, 중, 고등학교 여학생 BMI
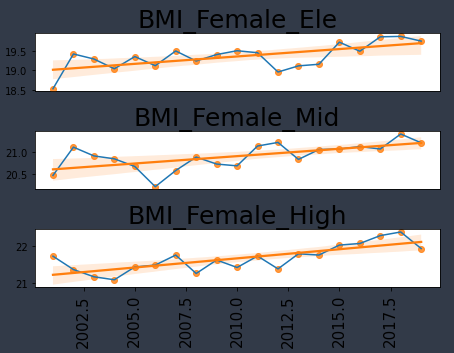
초, 중, 고등학교 여학생 모두 BMI 수치가 증가하고 있다.
남학생과 달리 여학생의 BMI 평균은 정상에 해당한다.
의외의 결과!
나는 초, 중, 고등학교 학생들 모두 예전과 비교해 키가 더 커졌을 거라 생각했다.
하지만 분석한 결과는 초, 중학생의 키는 증가하였으나 고등학생은 키는 그대로였다.
역시나!
비만율을 나타내는 BMI의 값은 초, 중, 고등학생 모두 증가했다.
아래는 소스코드.
소스코드 작성 후 반복문 쓸까 했는데... 반복문 안써도 크게 수정이 번거롭지 않아 그냥 여러번 반복해서 코드를 적음.
import os
path_dir = os.getcwd() #현재 디렉토리 확인
os.listdir(path_dir) #존재하는 파일 확인
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns #회귀분석을 위함
df = pd.read_csv(os.listdir(path_dir)[2]) #CSV 파일 불러오기
df_trans = df.transpose() #행, 열 바꾸기
df_trans.head() #5행까지 추출
#키_남자
year = np.array([float(i) for i in df_trans.iloc[3:, 0].index], dtype=float)
#초등
plt.figure(figsize=(len(df_trans.iloc[3:, 0].index)/3,5)) #그래프 크기 설정
plt.subplot(3,1,1) #그래프 전체 크기는 3행, 1열(1번째 그리기)
plt.plot(year, np.array(df_trans.iloc[3:, 0].values, dtype=float))
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 0].values, dtype=float))
plt.xticks([], []) #x축 안보이게 설정
plt.title("Height_Male_Ele", size=25)
plt.tight_layout() #그래프 겹치는 부분 없도록 설정
#중등
plt.subplot(3,1,2)
plt.plot(year, np.array(df_trans.iloc[3:, 4].values, dtype=float), c="r")
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 4].values, dtype=float))
plt.xticks([], [])
plt.title("Height_Male_Mid", size=25)
plt.tight_layout()
#고등
plt.subplot(3,1,3) #그래프 전체 크기는 3행, 1열(1번째 그리기)
plt.plot(year, np.array(df_trans.iloc[3:, 8].values, dtype=float), c="y")
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 8].values, dtype=float))
plt.title("Height_Male_High", size=25)
plt.xticks(rotation=90, size = 15)
plt.tight_layout() #그래프 겹치는 부분 없도록 설정
#키_여자
#초등
plt.figure(figsize=(len(df_trans.iloc[3:, 0].index)/3,5)) #그래프 크기 설정
plt.subplot(3,1,1) #그래프 전체 크기는 3행, 1열(1번째 그리기)
plt.plot(year, np.array(df_trans.iloc[3:, 1].values, dtype=float))
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 1].values, dtype=float))
plt.xticks([], []) #x축 안보이게 설정
plt.title("Height_Female_Ele", size=25)
plt.tight_layout() #그래프 겹치는 부분 없도록 설정
#중등
plt.subplot(3,1,2)
plt.plot(year, np.array(df_trans.iloc[3:, 5].values, dtype=float), c="r")
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 5].values, dtype=float))
plt.xticks([], [])
plt.title("Height_Female_Mid", size=25)
plt.tight_layout()
#고등
plt.subplot(3,1,3)
plt.plot(year, np.array(df_trans.iloc[3:, 9].values, dtype=float), c="y")
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 9].values, dtype=float))
plt.xticks(rotation=90, size = 15)
plt.title("Height_Female_High", size=25)
plt.tight_layout()
#BMI_남자
#초등
plt.figure(figsize=(len(df_trans.iloc[3:, 0].index)/3,5)) #그래프 크기 설정
plt.subplot(3,1,1) #그래프 전체 크기는 3행, 1열(1번째 그리기)
plt.plot(year, np.array(df_trans.iloc[3:, 2]/(df_trans.iloc[3:, 0]/100)**2, dtype=float))
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 2]/(df_trans.iloc[3:, 0]/100)**2, dtype=float))
plt.xticks([], []) #x축 안보이게 설정
plt.title("BMI_Male_Ele", size=25)
plt.tight_layout() #그래프 겹치는 부분 없도록 설정
#중등
plt.subplot(3,1,2)
plt.plot(year, np.array(df_trans.iloc[3:, 6]/(df_trans.iloc[3:, 4]/100)**2, dtype=float))
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 6]/(df_trans.iloc[3:, 4]/100)**2, dtype=float))
plt.xticks([], [])
plt.title("BMI_Male_Mid", size=25)
plt.tight_layout()
#고등
plt.subplot(3,1,3)
plt.plot(year, np.array(df_trans.iloc[3:, 10]/(df_trans.iloc[3:, 8]/100)**2, dtype=float))
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 10]/(df_trans.iloc[3:, 8]/100)**2, dtype=float))
plt.xticks(rotation=90, size = 15)
plt.title("BMI_Male_High", size=25)
plt.tight_layout()
#BMI_여자
#초등
plt.figure(figsize=(len(df_trans.iloc[3:, 0].index)/3,5)) #그래프 크기 설정
plt.subplot(3,1,1) #그래프 전체 크기는 3행, 1열(1번째 그리기)
plt.plot(year, np.array(df_trans.iloc[3:, 3]/(df_trans.iloc[3:, 1]/100)**2, dtype=float))
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 3]/(df_trans.iloc[3:, 1]/100)**2, dtype=float))
plt.xticks([], []) #x축 안보이게 설정
plt.title("BMI_Female_Ele", size=25)
plt.tight_layout() #그래프 겹치는 부분 없도록 설정
#중등
plt.subplot(3,1,2)
plt.plot(year, np.array(df_trans.iloc[3:, 7]/(df_trans.iloc[3:, 5]/100)**2, dtype=float))
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 7]/(df_trans.iloc[3:, 5]/100)**2, dtype=float))
plt.xticks([], [])
plt.title("BMI_Female_Mid", size=25)
plt.tight_layout()
#고등
plt.subplot(3,1,3)
plt.plot(year, np.array(df_trans.iloc[3:, 11]/(df_trans.iloc[3:, 9]/100)**2, dtype=float))
sns.regplot(x=year, y= np.array(df_trans.iloc[3:, 11]/(df_trans.iloc[3:, 9]/100)**2, dtype=float))
plt.xticks(rotation=90, size = 15)
plt.title("BMI_Female_High", size=25)
plt.tight_layout()'데이터 분석' 카테고리의 다른 글
| [데이터분석]엔화, 달러, 위안화는 함께 오를까? (0) | 2022.10.26 |
|---|---|
| [데이터분석]서울과 울란바토르의 교통사고 사망자, 부상자 비교 (2) | 2022.10.05 |
| [데이터분석]KTX, SRT 예매 경쟁률은 어느 정도일까? (2) | 2022.09.12 |
| [데이터분석]연도와 태풍 발생량은 상관이 있을까?(feat. 힌남노) (1) | 2022.09.06 |
| 한국 아동 및 청소년 데이터 사이트_한국 아동 청소년 데이터 아카이브 (0) | 2022.03.30 |




댓글